La régression logistique#
La régression linéaire est l'un des algorithmes les plus connus. Elle est toujours enseigné au lycée. Il permet de résoudre des problèmes de régression de type linéaire.

Définition#
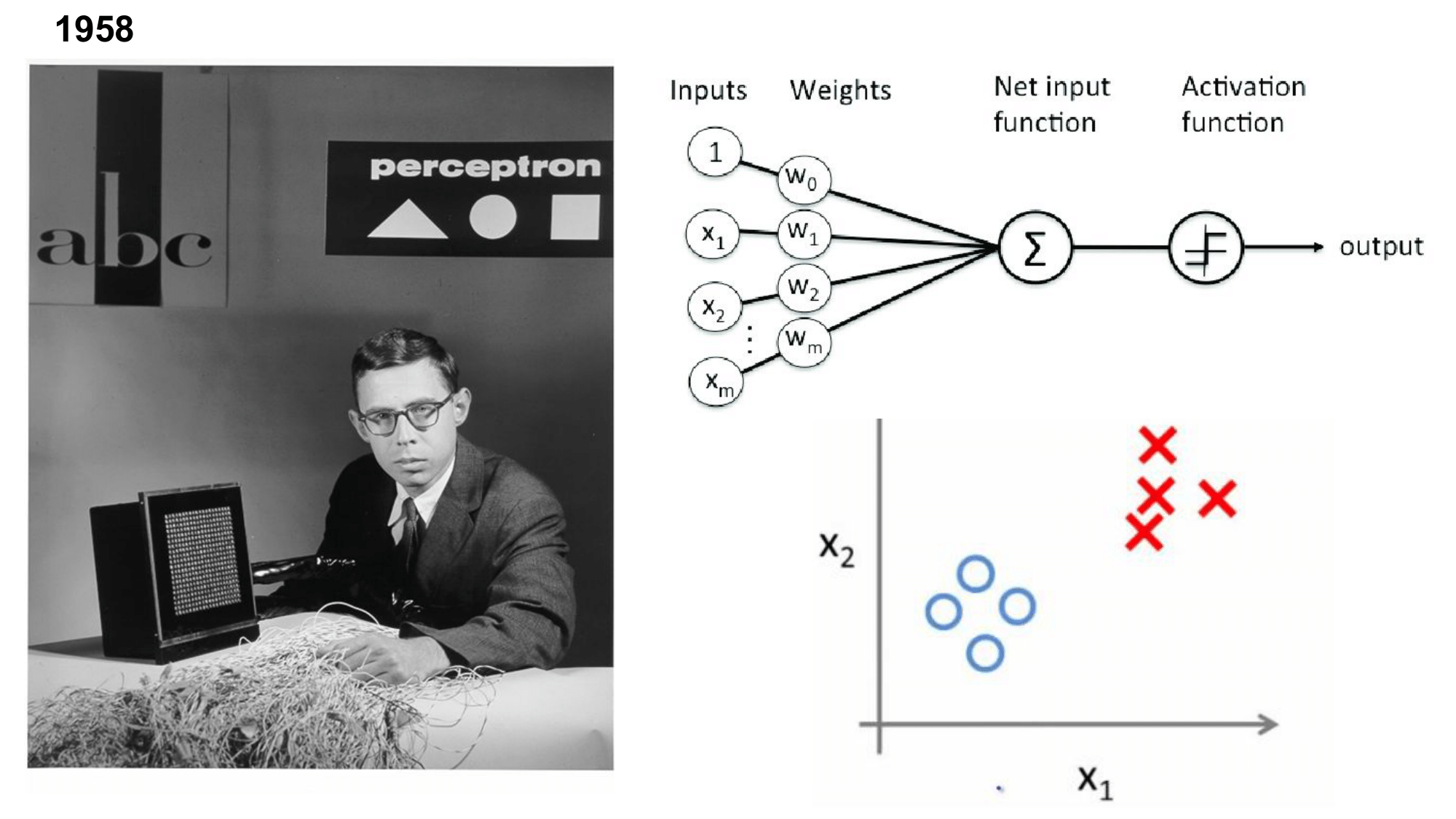
La régression logistique est un algorithme de classification binaire de type linéaire. Elle répond donc aux problèmes linéairement séparables c'est-à-dire qu'on peut séparer les points des deux clases avec une droite.
Binaire: deux classes Linéaire: on peut séparer les deux classes à l'aide d'une droite
La solution d'une régression s'obtient en minimisant l'entropie croisée binaire.
Librairies#
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, f1_score, confusion_matrix
Importation des données#
Le jeu de donnés contient des donnés récuellies chez des patients, il comporte 100 lignes et 9 colonnes. La colonne diagnosis_result est la variable à expliquer qui represente le resultat du diagnostic. Les 8 dernières colonnes représentent les variables explicatives.
Exploration#
Variable à expliquer#

Les classes M et B sont déséquilibrées M(62) et B(38), il faudra en tenir compte dans la suite. Un modèle naïf qui prédit la classe M aurait une accuracy de 62% sans avoir appris les données.
Variables explicatives#

Les variables ont des échelles (ou ordres de grandeur) différentes, il faut supprimer la dimension
Centrage et Réduction#
- Centrer une variable consiste à retrancher la moyenne de toutes les données, la nouvelle moyenne est 0.
- Réduire (ou normliser) une variable consiste à diviser toutes les données par l'écart-type, le nouvel écart-type est 1.



Encodage de la variable explicative#
On encode les valeurs B et M en 0 et 1.
Échantillonnage#
L'argument stratify c'est pour indiquer que l'on souhaite que la séparation soit équilibrée suivant la variable diagnosis_result.
Modélisation#
Évaluation#
Plusieurs métriques peuvent être utilsés pour évaluer un modèle de classification (binaire). Le plus utilsé est l'accuracy. * Accuracy: le taux de bonnes prédictions. Lorsque les classes sont déséquilibrées, elle peut être trompeuse. * Précision: le taux de bonnes prédictions sur les prédictions positives. * Rappel: le taux de bonnes prédictions sur les données positives. * F1_score:
y_pred = clf.predict(X_test)
acc = accuracy_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
confmat = confusion_matrix(y_test, y_pred)
print('Accuracy: %0.2f' % acc)
print('F1 score: %0.2f' % f1)
plt.matshow(confmat, cmap=plt.cm.Greens, alpha=.3)
for i in range(confmat.shape[0]):
for j in range(confmat.shape[1]):
plt.text(x=j, y=i, s=confmat[i, j], va='center', ha='center')
plt.xlabel('Valeur prédite')
plt.ylabel('Vraie valeur')
plt.show()

Interprétaion#
Le premier axe conserve 41,2% le deuxième axe 19,4% et le troisème axe 14,3%. Les trois axes permettent de conserver environ 75% de variance des données. Si l'on souhaite conserver plus de variance, on peut ajouter un axe supplémentaire ou plus. Remarquons qu'il est peu pertinent de conserver toute la variance, autant travailler avec les données initiales, il ne faut pas perdre de vue que l'un des objectifs de l'ACP, c'est la réduction du nombre de dimensions.
Code complet#
# coding : utf-8
'''
Scikit-learn Challenge
#02 : Logistic Regression
'''
# Packages
import pickle
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix
# Get data
X, y = make_classification(n_samples=100, n_features=4, n_classes=2)
# Design model
clf = LogisticRegression(penalty='l2', C=0.8)
# Train model
clf.fit(X, y)
# Evaluate model
y_pred = clf.predict(X)
score = accuracy_score(y, y_pred)
print('Accuracy score: ', round(score, 2))
conf_mat = confusion_matrix(y, y_pred)
print(conf_mat)
# Inference
output = clf.predict([[1.5, 0.24, 2.6, 0.1]])[0]
print('Predcited class: ', output)
# Save model
with open('output/model.pkl', 'wb') as f:
pickle.dump(obj=clf, file=f)
Pour signaler un problème que vous avez rencontré durant l'exécution des cahiers, merci de créer une issue. Assurez-vous que vous avez les bonnes versions des packages*