

Vous avez vu un table sur un site et vous souhaitez récupérer les données. Pandas et Beautiful Soup sont vos hommes. Dans ce tutoriel, je vous montre comment extraire les données d'une table à partir d'un site web sur internet.
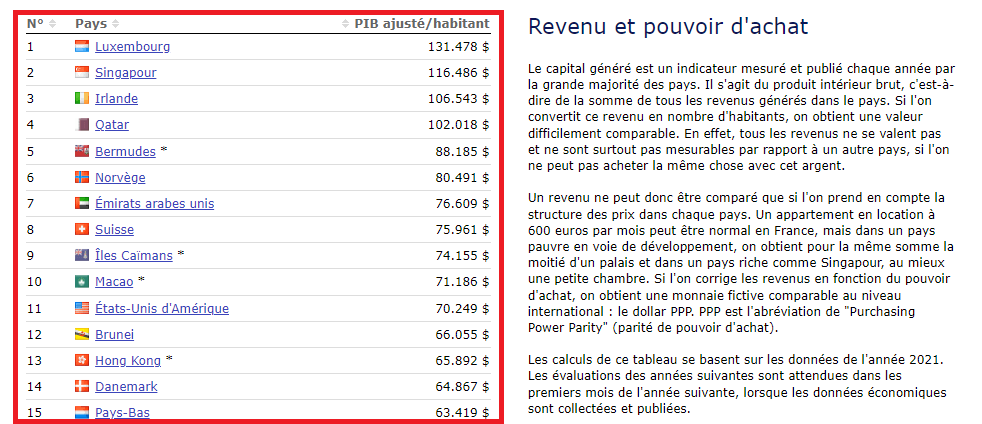
Ci-dessous, le tableau dont nous allons extraire les données https://www.donneesmondiales.com/pays-plus-riches.php.
Installer les packages#
Nous avons besoin de trois packages qu'il faut d'abord installer:
requests: pour récupérer le code source de la pageBeautifulSoup: pour identifier la tablepandas: pour lire les données du tableau, les transformer et les sauvegarder dans un fichier.
L'installion peut être faite depuis le dépôt PyPi
Astuce#
L'astuce consiste dans un premier temps à récupérer le code source (HTML) de la page web en question. Ensuite il faut extraire la section qui correspond au tableau (<table> --- </table>) et passer ce bout de code à Pandas qui lira le tableau pour retourner un dataframe.
Implémentation#
On commence par importer les packages
Il est commun de mettre l'URL de la page dans une constante, on indique également le nom du fichier de sauvegarde.
# Paths
DATA_URL = "https://www.donneesmondiales.com/pays-plus-riches.php"
OUTPUT_FILE = "./pays-plus-riches.csv"
On va utiliser Requests pour récupérer le code source de la page web qui contient le tableau dont nous voulons extraire les données.
Une fois le code source récupéré, on convertit en objet Beautiful Soup afin de pouvoir naviguer dans les éléments HTML.
Il faut spécifier le type de balise et bien évidemment, il s'agit d'une balise table et les propriétés CSS qui permettraient d'indentifier de manière unique la table qui nous intéresse. pour cela, il faut inspecter le code source de la page et récupérer les propriétés CSS, class et id sont les plus utilisées.
On passe l'élément table à Pandas qui va y extraire les données dans un dataframe. pandas.read_html retourne une liste de dataframes (un seul dans notre cas), on ajoute donc [0] pour récupérer le dataframe.
N° Pays PIB ajusté/habitant
0 1 Luxembourg 131.478 $
1 2 Singapour 116.486 $
2 3 Irlande 106.543 $
3 4 Qatar 102.018 $
4 5 Bermudes * 88.185 $
5 6 Norvège 80.491 $
6 7 Émirats arabes unis 76.609 $
7 8 Suisse 75.961 $
8 9 Îles Caïmans * 74.155 $
9 10 Macao * 71.186 $
Il ne vous reste plus qu'à enrégistrer vos données, dans un fichier CSV pour l'exemple
Code complet#
# Packages
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Paths
DATA_URL = "https://www.donneesmondiales.com/pays-plus-riches.php"
OUTPUT_FILE = "./pays-plus-riches.csv"
# Retreive source code
source = requests.get(DATA_URL)
# Convert into bs4 object
soup = BeautifulSoup(source.text, "html.parser")
# Extract table (specify table css properties)
table = soup.find("table", {"id": "tabsort"})
# Get data into dataframe
data = pd.read_html(str(table))[0]
# Export to CSV file
data.to_csv(OUTPUT_FILE, index=False)
Références#
- Pandas : https://pandas.pydata.org/docs/
- Requests : https://requests.readthedocs.io/en/latest/
- BeautifulSoup : https://www.crummy.com/software/BeautifulSoup/bs4/doc/
.
Commentaires