
Docker Compose#
https://hub.docker.com/r/bitnami/spark
apache-spark
https://github.com/bitnami/containers/blob/main/bitnami/spark/docker-compose.yml
Installer Java#
Apache Spark étant dévelopée en Java, nous devons installer Java. Si vous l'avez déjà installé alors vous pouvez passer cette étape, sinon suivez ce tutoriel pour effectuer l'installation.
Pour Linux
Installer Java
Définir la variable d'environnement
Installer Apache Spark#
Installer Java
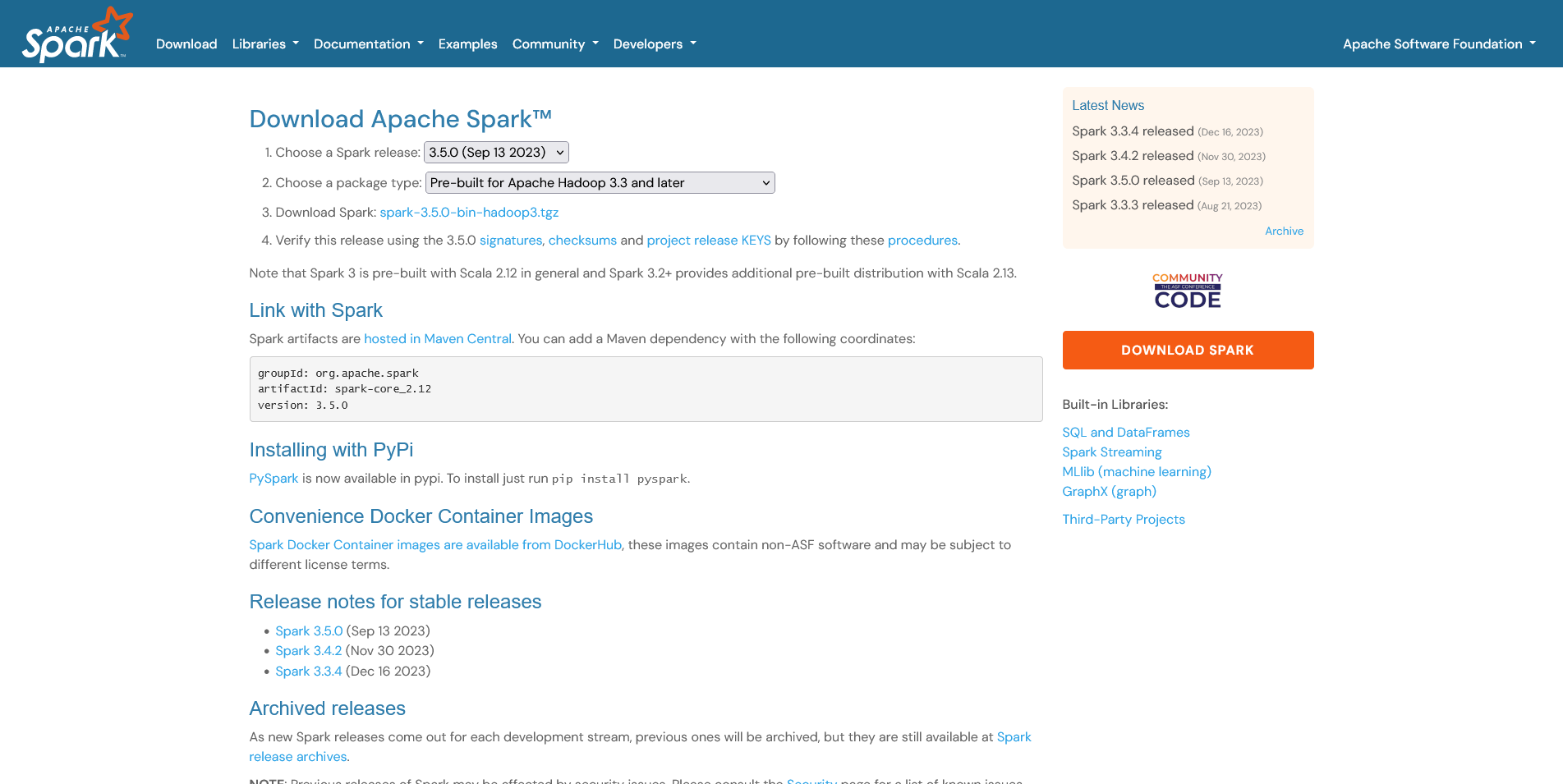
Rendez-vous à la page de télechargement Download Apache Spark™
Définir la variable d'environnement
Démarrer Spark#
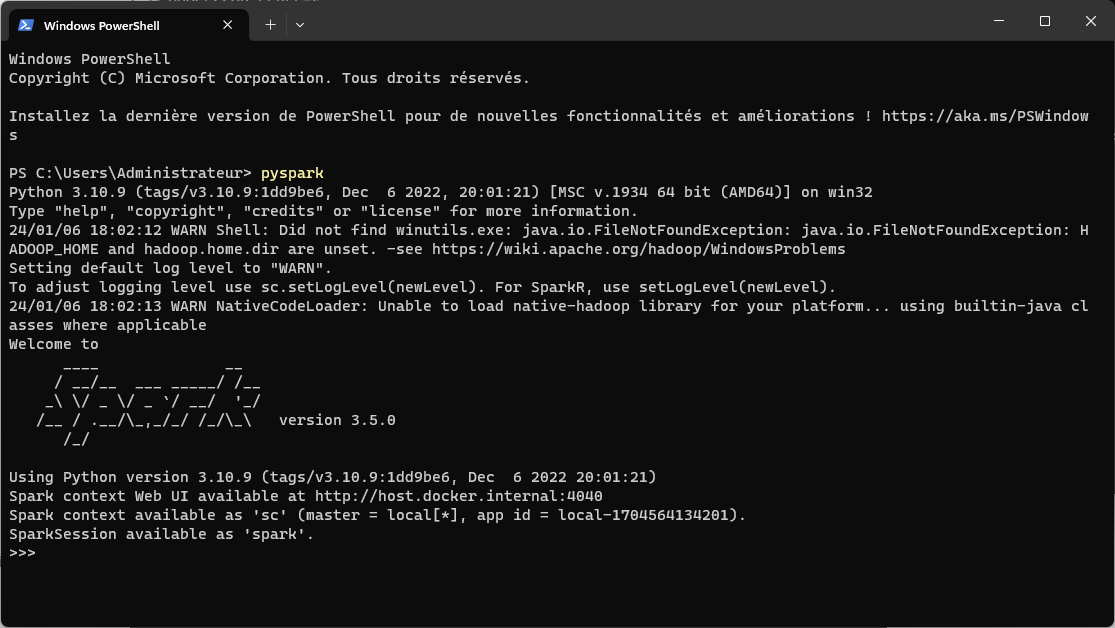
Ouvrez le terminal et lancez la commande suivante pyspark
Ouvrez le navigateur et rendez-vous à cette adresse http://host.docker.internal:4040
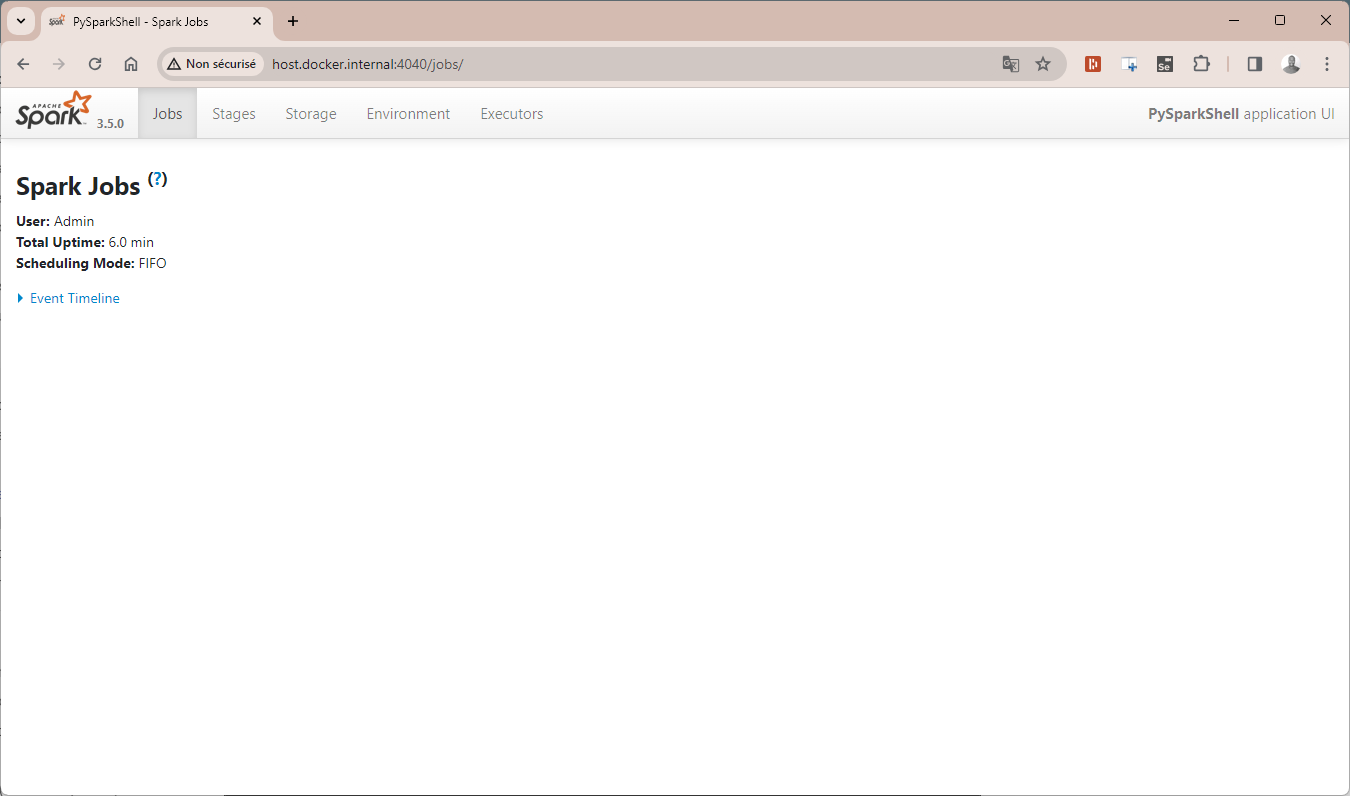
Parfait ! Le moteur Spark est opérationnel sur votre machine, il ne nous reste plus qu'à installer le package PySpark pour
apt-get update && apt-get install -y iputils-ping
echo $PYSPARK_PYTHON && echo $PYSPARK_DRIVER_PYTHON
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("MonPremiereApplicationSpark") \
.getOrCreate()
data = [("Alice", 1), ("Bob", 2), ("Charlie", 3)]
df = spark.createDataFrame(data, ["Name", "ID"])
df.show()
spark.stop()
docker cp first_spark_app.py spark-master:/opt/bitnami/spark/
docker cp first_spark_app.py jupyterhub:/srv/jupyterhub/
spark-submit --master spark://spark-master:7077 /opt/bitnami/spark/first_spark_app.py
spark-submit --master spark://spark-master:7077 /srv/jupyterhub/first_spark_app.py
root@spark-master:/opt/bitnami/spark# spark-submit --master spark://spark-master:7077 /opt/bitnami/spark/first_spark_app.py
25/07/05 18:28:41 INFO SparkContext: Running Spark version 3.5.6
25/07/05 18:28:41 INFO SparkContext: OS info Linux, 5.14.0-162.23.1.el9_1.x86_64, amd64
25/07/05 18:28:41 INFO SparkContext: Java version 17.0.15
25/07/05 18:28:41 INFO ResourceUtils: ==============================================================
25/07/05 18:28:41 INFO ResourceUtils: No custom resources configured for spark.driver.
25/07/05 18:28:41 INFO ResourceUtils: ==============================================================
25/07/05 18:28:41 INFO SparkContext: Submitted application: MonPremiereApplicationSpark
25/07/05 18:28:41 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(memory -> name: memory, amount: 1024, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
25/07/05 18:28:41 INFO ResourceProfile: Limiting resource is cpu
25/07/05 18:28:41 INFO ResourceProfileManager: Added ResourceProfile id: 0
25/07/05 18:28:41 INFO SecurityManager: Changing view acls to: root,spark
25/07/05 18:28:41 INFO SecurityManager: Changing modify acls to: root,spark
25/07/05 18:28:41 INFO SecurityManager: Changing view acls groups to:
25/07/05 18:28:41 INFO SecurityManager: Changing modify acls groups to:
25/07/05 18:28:41 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: root, spark; groups with view permissions: EMPTY; users with modify permissions: root, spark; groups with modify permissions: EMPTY
25/07/05 18:28:41 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
25/07/05 18:28:42 INFO Utils: Successfully started service 'sparkDriver' on port 33497.
25/07/05 18:28:42 INFO SparkEnv: Registering MapOutputTracker
25/07/05 18:28:42 INFO SparkEnv: Registering BlockManagerMaster
25/07/05 18:28:42 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
25/07/05 18:28:42 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
25/07/05 18:28:42 INFO SparkEnv: Registering BlockManagerMasterHeartbeat
25/07/05 18:28:42 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-2a51a9e2-490f-414b-9a6a-78a659310f3d
25/07/05 18:28:42 INFO MemoryStore: MemoryStore started with capacity 434.4 MiB
25/07/05 18:28:42 INFO SparkEnv: Registering OutputCommitCoordinator
25/07/05 18:28:42 INFO JettyUtils: Start Jetty 0.0.0.0:4040 for SparkUI
25/07/05 18:28:42 INFO Utils: Successfully started service 'SparkUI' on port 4040.
25/07/05 18:28:42 INFO StandaloneAppClient$ClientEndpoint: Connecting to master spark://spark-master:7077...
25/07/05 18:28:42 INFO TransportClientFactory: Successfully created connection to spark-master/172.24.0.2:7077 after 42 ms (0 ms spent in bootstraps)
25/07/05 18:28:42 INFO StandaloneSchedulerBackend: Connected to Spark cluster with app ID app-20250705182842-0001
25/07/05 18:28:43 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20250705182842-0001/0 on worker-20250705181958-172.24.0.4-41281 (172.24.0.4:41281) with 1 core(s)
25/07/05 18:28:43 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 45779.
25/07/05 18:28:43 INFO NettyBlockTransferService: Server created on spark-master:45779
25/07/05 18:28:43 INFO StandaloneSchedulerBackend: Granted executor ID app-20250705182842-0001/0 on hostPort 172.24.0.4:41281 with 1 core(s), 1024.0 MiB RAM
25/07/05 18:28:43 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20250705182842-0001/1 on worker-20250705181958-172.24.0.3-37221 (172.24.0.3:37221) with 1 core(s)
25/07/05 18:28:43 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
25/07/05 18:28:43 INFO StandaloneSchedulerBackend: Granted executor ID app-20250705182842-0001/1 on hostPort 172.24.0.3:37221 with 1 core(s), 1024.0 MiB RAM
25/07/05 18:28:43 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, spark-master, 45779, None)
25/07/05 18:28:43 INFO BlockManagerMasterEndpoint: Registering block manager spark-master:45779 with 434.4 MiB RAM, BlockManagerId(driver, spark-master, 45779, None)
25/07/05 18:28:43 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, spark-master, 45779, None)
25/07/05 18:28:43 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, spark-master, 45779, None)
25/07/05 18:28:43 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20250705182842-0001/0 is now RUNNING
25/07/05 18:28:43 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20250705182842-0001/1 is now RUNNING
25/07/05 18:28:43 INFO StandaloneSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
25/07/05 18:28:43 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir.
25/07/05 18:28:43 INFO SharedState: Warehouse path is 'file:/opt/bitnami/spark/spark-warehouse'.
25/07/05 18:28:45 INFO StandaloneSchedulerBackend$StandaloneDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.24.0.4:44160) with ID 0, ResourceProfileId 0
25/07/05 18:28:46 INFO StandaloneSchedulerBackend$StandaloneDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.24.0.3:50730) with ID 1, ResourceProfileId 0
25/07/05 18:28:46 INFO BlockManagerMasterEndpoint: Registering block manager 172.24.0.4:35683 with 434.4 MiB RAM, BlockManagerId(0, 172.24.0.4, 35683, None)
25/07/05 18:28:46 INFO BlockManagerMasterEndpoint: Registering block manager 172.24.0.3:43267 with 434.4 MiB RAM, BlockManagerId(1, 172.24.0.3, 43267, None)
25/07/05 18:28:46 INFO CodeGenerator: Code generated in 198.646755 ms
25/07/05 18:28:46 INFO SparkContext: Starting job: showString at <unknown>:0
25/07/05 18:28:46 INFO DAGScheduler: Got job 0 (showString at <unknown>:0) with 1 output partitions
25/07/05 18:28:46 INFO DAGScheduler: Final stage: ResultStage 0 (showString at <unknown>:0)
25/07/05 18:28:46 INFO DAGScheduler: Parents of final stage: List()
25/07/05 18:28:46 INFO DAGScheduler: Missing parents: List()
25/07/05 18:28:46 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[6] at showString at <unknown>:0), which has no missing parents
25/07/05 18:28:46 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 12.6 KiB, free 434.4 MiB)
25/07/05 18:28:46 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 6.6 KiB, free 434.4 MiB)
25/07/05 18:28:46 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on spark-master:45779 (size: 6.6 KiB, free: 434.4 MiB)
25/07/05 18:28:46 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1611
25/07/05 18:28:46 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (MapPartitionsRDD[6] at showString at <unknown>:0) (first 15 tasks are for partitions Vector(0))
25/07/05 18:28:46 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks resource profile 0
25/07/05 18:28:46 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0) (172.24.0.3, executor 1, partition 0, PROCESS_LOCAL, 9020 bytes)
25/07/05 18:28:47 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 172.24.0.3:43267 (size: 6.6 KiB, free: 434.4 MiB)
25/07/05 18:28:49 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 2984 ms on 172.24.0.3 (executor 1) (1/1)
25/07/05 18:28:49 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
25/07/05 18:28:49 INFO PythonAccumulatorV2: Connected to AccumulatorServer at host: 127.0.0.1 port: 51505
25/07/05 18:28:49 INFO DAGScheduler: ResultStage 0 (showString at <unknown>:0) finished in 3.169 s
25/07/05 18:28:49 INFO DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
25/07/05 18:28:49 INFO TaskSchedulerImpl: Killing all running tasks in stage 0: Stage finished
25/07/05 18:28:49 INFO DAGScheduler: Job 0 finished: showString at <unknown>:0, took 3.206109 s
25/07/05 18:28:49 INFO SparkContext: Starting job: showString at <unknown>:0
25/07/05 18:28:49 INFO DAGScheduler: Got job 1 (showString at <unknown>:0) with 1 output partitions
25/07/05 18:28:49 INFO DAGScheduler: Final stage: ResultStage 1 (showString at <unknown>:0)
25/07/05 18:28:49 INFO DAGScheduler: Parents of final stage: List()
25/07/05 18:28:49 INFO DAGScheduler: Missing parents: List()
25/07/05 18:28:49 INFO DAGScheduler: Submitting ResultStage 1 (MapPartitionsRDD[6] at showString at <unknown>:0), which has no missing parents
25/07/05 18:28:49 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 12.6 KiB, free 434.4 MiB)
25/07/05 18:28:49 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 6.6 KiB, free 434.4 MiB)
25/07/05 18:28:49 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on spark-master:45779 (size: 6.6 KiB, free: 434.4 MiB)
25/07/05 18:28:49 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1611
25/07/05 18:28:49 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[6] at showString at <unknown>:0) (first 15 tasks are for partitions Vector(1))
25/07/05 18:28:49 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks resource profile 0
25/07/05 18:28:49 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1) (172.24.0.4, executor 0, partition 1, PROCESS_LOCAL, 9057 bytes)
25/07/05 18:28:49 INFO BlockManagerInfo: Removed broadcast_0_piece0 on spark-master:45779 in memory (size: 6.6 KiB, free: 434.4 MiB)
25/07/05 18:28:49 INFO BlockManagerInfo: Removed broadcast_0_piece0 on 172.24.0.3:43267 in memory (size: 6.6 KiB, free: 434.4 MiB)
25/07/05 18:28:49 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 172.24.0.4:35683 (size: 6.6 KiB, free: 434.4 MiB)
25/07/05 18:28:52 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 2570 ms on 172.24.0.4 (executor 0) (1/1)
25/07/05 18:28:52 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
25/07/05 18:28:52 INFO DAGScheduler: ResultStage 1 (showString at <unknown>:0) finished in 2.585 s
25/07/05 18:28:52 INFO DAGScheduler: Job 1 is finished. Cancelling potential speculative or zombie tasks for this job
25/07/05 18:28:52 INFO TaskSchedulerImpl: Killing all running tasks in stage 1: Stage finished
25/07/05 18:28:52 INFO DAGScheduler: Job 1 finished: showString at <unknown>:0, took 2.590749 s
25/07/05 18:28:53 INFO BlockManagerInfo: Removed broadcast_1_piece0 on spark-master:45779 in memory (size: 6.6 KiB, free: 434.4 MiB)
25/07/05 18:28:53 INFO BlockManagerInfo: Removed broadcast_1_piece0 on 172.24.0.4:35683 in memory (size: 6.6 KiB, free: 434.4 MiB)
25/07/05 18:28:53 INFO CodeGenerator: Code generated in 19.74549 ms
+-------+---+
| Name| ID|
+-------+---+
| Alice| 1|
| Bob| 2|
|Charlie| 3|
+-------+---+
25/07/05 18:28:53 INFO SparkContext: SparkContext is stopping with exitCode 0.
25/07/05 18:28:53 INFO SparkUI: Stopped Spark web UI at http://spark-master:4040
25/07/05 18:28:53 INFO StandaloneSchedulerBackend: Shutting down all executors
25/07/05 18:28:53 INFO StandaloneSchedulerBackend$StandaloneDriverEndpoint: Asking each executor to shut down
25/07/05 18:28:53 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
25/07/05 18:28:53 INFO MemoryStore: MemoryStore cleared
25/07/05 18:28:53 INFO BlockManager: BlockManager stopped
25/07/05 18:28:53 INFO BlockManagerMaster: BlockManagerMaster stopped
25/07/05 18:28:53 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
25/07/05 18:28:53 INFO SparkContext: Successfully stopped SparkContext
25/07/05 18:28:54 INFO ShutdownHookManager: Shutdown hook called
25/07/05 18:28:54 INFO ShutdownHookManager: Deleting directory /tmp/spark-76cf0c77-65c9-4cf0-b76a-1d7036d239a5
25/07/05 18:28:54 INFO ShutdownHookManager: Deleting directory /tmp/spark-bb9d8cb2-7ceb-459c-912f-62a1f65d2c46
25/07/05 18:28:54 INFO ShutdownHookManager: Deleting directory /tmp/spark-76cf0c77-65c9-4cf0-b76a-1d7036d239a5/pyspark-e85ad4aa-5506-443c-b340-91896717d234
root@jupyterhub:/srv/jupyterhub# spark-submit --master spark://spark-master:7077 /srv/jupyterhub/first_spark_app.py
25/07/06 19:40:14 INFO SparkContext: Running Spark version 3.5.6
25/07/06 19:40:14 INFO SparkContext: OS info Linux, 5.14.0-162.23.1.el9_1.x86_64, amd64
25/07/06 19:40:14 INFO SparkContext: Java version 17.0.15
25/07/06 19:40:14 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
25/07/06 19:40:14 INFO ResourceUtils: ==============================================================
25/07/06 19:40:14 INFO ResourceUtils: No custom resources configured for spark.driver.
25/07/06 19:40:14 INFO ResourceUtils: ==============================================================
25/07/06 19:40:14 INFO SparkContext: Submitted application: DebugJupyterSpark
25/07/06 19:40:14 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(memory -> name: memory, amount: 1024, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
25/07/06 19:40:14 INFO ResourceProfile: Limiting resource is cpu
25/07/06 19:40:14 INFO ResourceProfileManager: Added ResourceProfile id: 0
25/07/06 19:40:14 INFO SecurityManager: Changing view acls to: root
25/07/06 19:40:14 INFO SecurityManager: Changing modify acls to: root
25/07/06 19:40:14 INFO SecurityManager: Changing view acls groups to:
25/07/06 19:40:14 INFO SecurityManager: Changing modify acls groups to:
25/07/06 19:40:14 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: root; groups with view permissions: EMPTY; users with modify permissions: root; groups with modify permissions: EMPTY
25/07/06 19:40:14 INFO Utils: Successfully started service 'sparkDriver' on port 40400.
25/07/06 19:40:14 INFO SparkEnv: Registering MapOutputTracker
25/07/06 19:40:14 INFO SparkEnv: Registering BlockManagerMaster
25/07/06 19:40:14 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
25/07/06 19:40:14 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
25/07/06 19:40:14 INFO SparkEnv: Registering BlockManagerMasterHeartbeat
25/07/06 19:40:14 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-deb82f12-ad25-4c70-95fa-22550602b348
25/07/06 19:40:14 INFO MemoryStore: MemoryStore started with capacity 434.4 MiB
25/07/06 19:40:14 INFO SparkEnv: Registering OutputCommitCoordinator
25/07/06 19:40:15 INFO JettyUtils: Start Jetty 0.0.0.0:4040 for SparkUI
25/07/06 19:40:15 INFO Utils: Successfully started service 'SparkUI' on port 4040.
25/07/06 19:40:15 INFO StandaloneAppClient$ClientEndpoint: Connecting to master spark://spark-master:7077...
25/07/06 19:40:15 INFO TransportClientFactory: Successfully created connection to spark-master/172.25.0.2:7077 after 32 ms (0 ms spent in bootstraps)
25/07/06 19:40:15 INFO StandaloneSchedulerBackend: Connected to Spark cluster with app ID app-20250706194015-0000
25/07/06 19:40:15 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 40401.
25/07/06 19:40:15 INFO NettyBlockTransferService: Server created on jupyterhub 0.0.0.0:40401
25/07/06 19:40:15 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
25/07/06 19:40:15 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, jupyterhub, 40401, None)
25/07/06 19:40:15 INFO BlockManagerMasterEndpoint: Registering block manager jupyterhub:40401 with 434.4 MiB RAM, BlockManagerId(driver, jupyterhub, 40401, None)
25/07/06 19:40:15 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, jupyterhub, 40401, None)
25/07/06 19:40:15 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, jupyterhub, 40401, None)
25/07/06 19:40:15 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20250706194015-0000/0 on worker-20250706193932-172.25.0.4-42009 (172.25.0.4:42009) with 1 core(s)
25/07/06 19:40:15 INFO StandaloneSchedulerBackend: Granted executor ID app-20250706194015-0000/0 on hostPort 172.25.0.4:42009 with 1 core(s), 1024.0 MiB RAM
25/07/06 19:40:15 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20250706194015-0000/1 on worker-20250706193931-172.25.0.3-39455 (172.25.0.3:39455) with 1 core(s)
25/07/06 19:40:15 INFO StandaloneSchedulerBackend: Granted executor ID app-20250706194015-0000/1 on hostPort 172.25.0.3:39455 with 1 core(s), 1024.0 MiB RAM
25/07/06 19:40:15 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20250706194015-0000/0 is now RUNNING
25/07/06 19:40:15 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20250706194015-0000/1 is now RUNNING
25/07/06 19:40:15 INFO StandaloneSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
25/07/06 19:40:16 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir.
25/07/06 19:40:16 INFO SharedState: Warehouse path is 'file:/srv/jupyterhub/spark-warehouse'.
25/07/06 19:40:18 INFO StandaloneSchedulerBackend$StandaloneDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.25.0.4:49356) with ID 0, ResourceProfileId 0
25/07/06 19:40:18 INFO StandaloneSchedulerBackend$StandaloneDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.25.0.3:51278) with ID 1, ResourceProfileId 0
25/07/06 19:40:18 INFO BlockManagerMasterEndpoint: Registering block manager 172.25.0.4:40401 with 434.4 MiB RAM, BlockManagerId(0, 172.25.0.4, 40401, None)
25/07/06 19:40:18 INFO BlockManagerMasterEndpoint: Registering block manager 172.25.0.3:40401 with 434.4 MiB RAM, BlockManagerId(1, 172.25.0.3, 40401, None)
25/07/06 19:40:18 INFO CodeGenerator: Code generated in 230.527172 ms
25/07/06 19:40:19 INFO SparkContext: Starting job: showString at NativeMethodAccessorImpl.java:0
25/07/06 19:40:19 INFO DAGScheduler: Got job 0 (showString at NativeMethodAccessorImpl.java:0) with 1 output partitions
25/07/06 19:40:19 INFO DAGScheduler: Final stage: ResultStage 0 (showString at NativeMethodAccessorImpl.java:0)
25/07/06 19:40:19 INFO DAGScheduler: Parents of final stage: List()
25/07/06 19:40:19 INFO DAGScheduler: Missing parents: List()
25/07/06 19:40:19 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[6] at showString at NativeMethodAccessorImpl.java:0), which has no missing parents
25/07/06 19:40:19 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 12.7 KiB, free 434.4 MiB)
25/07/06 19:40:19 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 6.7 KiB, free 434.4 MiB)
25/07/06 19:40:19 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on jupyterhub:40401 (size: 6.7 KiB, free: 434.4 MiB)
25/07/06 19:40:19 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1611
25/07/06 19:40:19 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (MapPartitionsRDD[6] at showString at NativeMethodAccessorImpl.java:0) (first 15 tasks are for partitions Vector(0))
25/07/06 19:40:19 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks resource profile 0
25/07/06 19:40:19 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0) (172.25.0.4, executor 0, partition 0, PROCESS_LOCAL, 9020 bytes)
25/07/06 19:40:19 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 172.25.0.4:40401 (size: 6.7 KiB, free: 434.4 MiB)
25/07/06 19:40:21 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 2603 ms on 172.25.0.4 (executor 0) (1/1)
25/07/06 19:40:21 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
25/07/06 19:40:21 INFO PythonAccumulatorV2: Connected to AccumulatorServer at host: 127.0.0.1 port: 40285
25/07/06 19:40:21 INFO DAGScheduler: ResultStage 0 (showString at NativeMethodAccessorImpl.java:0) finished in 2.773 s
25/07/06 19:40:21 INFO DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
25/07/06 19:40:21 INFO TaskSchedulerImpl: Killing all running tasks in stage 0: Stage finished
25/07/06 19:40:21 INFO DAGScheduler: Job 0 finished: showString at NativeMethodAccessorImpl.java:0, took 2.822448 s
25/07/06 19:40:21 INFO SparkContext: Starting job: showString at NativeMethodAccessorImpl.java:0
25/07/06 19:40:21 INFO DAGScheduler: Got job 1 (showString at NativeMethodAccessorImpl.java:0) with 1 output partitions
25/07/06 19:40:21 INFO DAGScheduler: Final stage: ResultStage 1 (showString at NativeMethodAccessorImpl.java:0)
25/07/06 19:40:21 INFO DAGScheduler: Parents of final stage: List()
25/07/06 19:40:21 INFO DAGScheduler: Missing parents: List()
25/07/06 19:40:21 INFO DAGScheduler: Submitting ResultStage 1 (MapPartitionsRDD[6] at showString at NativeMethodAccessorImpl.java:0), which has no missing parents
25/07/06 19:40:21 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 12.7 KiB, free 434.4 MiB)
25/07/06 19:40:21 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 6.7 KiB, free 434.4 MiB)
25/07/06 19:40:21 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on jupyterhub:40401 (size: 6.7 KiB, free: 434.4 MiB)
25/07/06 19:40:21 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1611
25/07/06 19:40:21 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[6] at showString at NativeMethodAccessorImpl.java:0) (first 15 tasks are for partitions Vector(1))
25/07/06 19:40:21 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks resource profile 0
25/07/06 19:40:21 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1) (172.25.0.4, executor 0, partition 1, PROCESS_LOCAL, 9057 bytes)
25/07/06 19:40:21 INFO BlockManagerInfo: Removed broadcast_0_piece0 on jupyterhub:40401 in memory (size: 6.7 KiB, free: 434.4 MiB)
25/07/06 19:40:21 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 172.25.0.4:40401 (size: 6.7 KiB, free: 434.4 MiB)
25/07/06 19:40:21 INFO BlockManagerInfo: Removed broadcast_0_piece0 on 172.25.0.4:40401 in memory (size: 6.7 KiB, free: 434.4 MiB)
25/07/06 19:40:22 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 182 ms on 172.25.0.4 (executor 0) (1/1)
25/07/06 19:40:22 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
25/07/06 19:40:22 INFO DAGScheduler: ResultStage 1 (showString at NativeMethodAccessorImpl.java:0) finished in 0.206 s
25/07/06 19:40:22 INFO DAGScheduler: Job 1 is finished. Cancelling potential speculative or zombie tasks for this job
25/07/06 19:40:22 INFO TaskSchedulerImpl: Killing all running tasks in stage 1: Stage finished
25/07/06 19:40:22 INFO DAGScheduler: Job 1 finished: showString at NativeMethodAccessorImpl.java:0, took 0.216567 s
25/07/06 19:40:22 INFO BlockManagerInfo: Removed broadcast_1_piece0 on jupyterhub:40401 in memory (size: 6.7 KiB, free: 434.4 MiB)
25/07/06 19:40:22 INFO BlockManagerInfo: Removed broadcast_1_piece0 on 172.25.0.4:40401 in memory (size: 6.7 KiB, free: 434.4 MiB)
25/07/06 19:40:23 INFO CodeGenerator: Code generated in 17.154848 ms
+-------+---+
| Name| ID|
+-------+---+
| Alice| 1|
| Bob| 2|
|Charlie| 3|
+-------+---+
25/07/06 19:40:23 INFO SparkContext: SparkContext is stopping with exitCode 0.
25/07/06 19:40:23 INFO SparkUI: Stopped Spark web UI at http://jupyterhub:4040
25/07/06 19:40:23 INFO StandaloneSchedulerBackend: Shutting down all executors
25/07/06 19:40:23 INFO StandaloneSchedulerBackend$StandaloneDriverEndpoint: Asking each executor to shut down
25/07/06 19:40:23 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
25/07/06 19:40:23 INFO MemoryStore: MemoryStore cleared
25/07/06 19:40:23 INFO BlockManager: BlockManager stopped
25/07/06 19:40:23 INFO BlockManagerMaster: BlockManagerMaster stopped
25/07/06 19:40:23 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
25/07/06 19:40:23 INFO SparkContext: Successfully stopped SparkContext
25/07/06 19:40:24 INFO ShutdownHookManager: Shutdown hook called
25/07/06 19:40:24 INFO ShutdownHookManager: Deleting directory /tmp/spark-0193a676-f313-464e-be74-d369715a4b22/pyspark-9dbaa827-430f-4312-95e1-5659de6210f5
25/07/06 19:40:24 INFO ShutdownHookManager: Deleting directory /tmp/spark-0193a676-f313-464e-be74-d369715a4b22
25/07/06 19:40:24 INFO ShutdownHookManager: Deleting directory /tmp/spark-3e86e365-966c-461c-8888-7afa5d132904
Créer un environnement virtuel#
Lancez Anaconda Prompt et faites la commande suivante:
Cette commande va créer une environnement virtuel avec le nom spark, tapez y pour confirmer la création.
Une fois l'environnement virtuel créé, il faut l'activer avec la commande suivante.
Installer PySpark#
PySpark peut-être installé depuis le gestionnaire de packages Pypi. Pour cela tapez la commande suivante
Installer JupyterLab#
Les notebooks offrent un environnement interactif idéal pour travail avec PySpark.
Lancer JupyterLab#
Une fois l'installation terminée, lancez la commande suivante
Créez un notebook
Commentaires